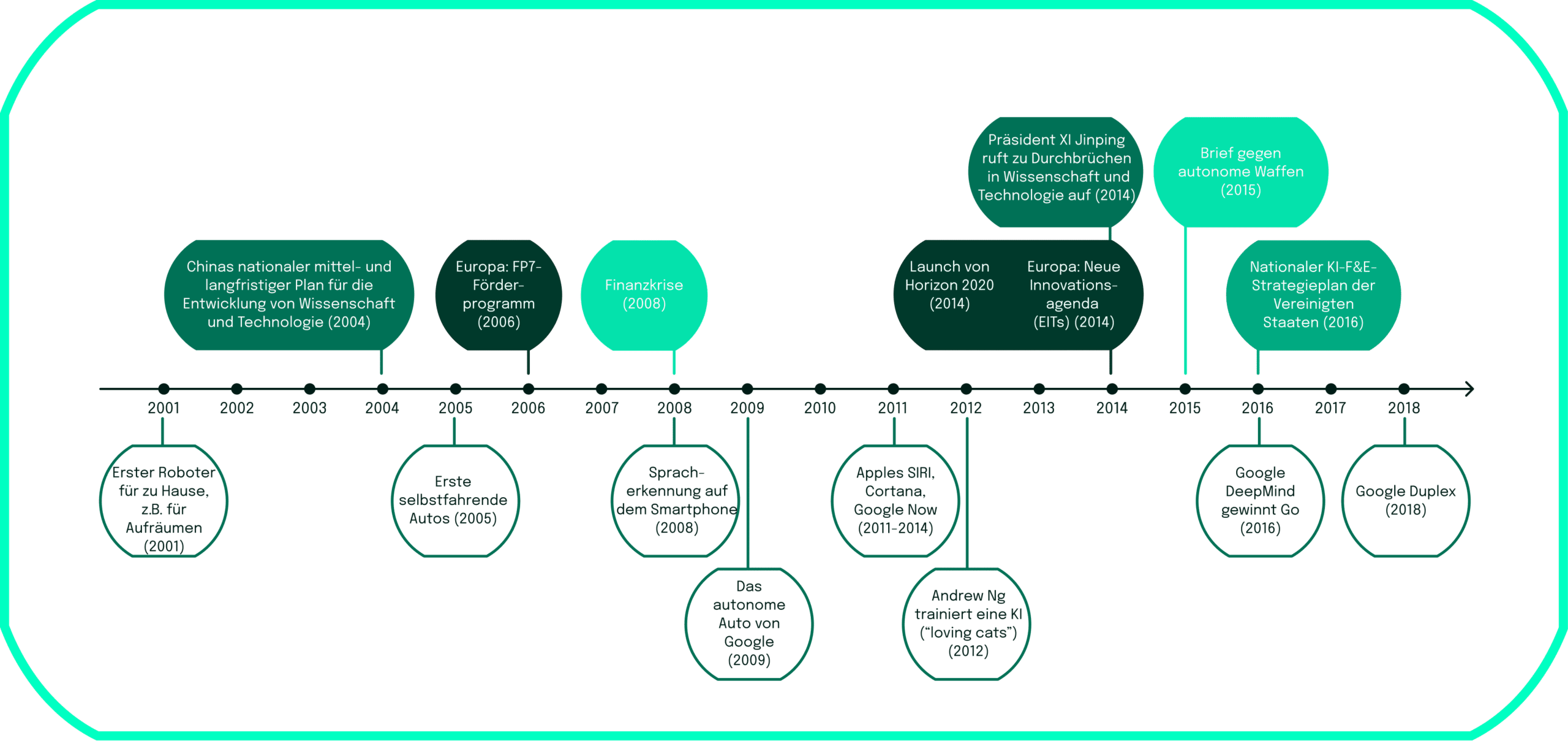
Ob in der Daily Show mit Trevor Noah, die Software Dall-E 2, welche Text in Bilder umwandelt, ChatGPT oder in noch umstritteneren technologischen Anwendungen der Künstlichen Intelligenz (KI) wie in tödlichen autonomen Waffensystemen (LAWS) – KI hat das Potenzial, unser tägliches Leben in naher Zukunft zu verändern. Die Anwendung von KI-Technologien treibt das Wachstum auf individueller, geschäftlicher und wirtschaftlicher Ebene voran. Tatsächlich hat die Geschichte der künstlichen intelligenz begonnen, den Menschen bei einer Reihe von Arbeitstätigkeiten zu übertreffen.

Da der weltweite KI-Markt laut McKinsey einen Jahresumsatz von fast 32 Billionen Dollar erreichen soll, boomt die Branche und dehnt sich auf noch breitere Anwendungsbereiche aus. In den vergangenen Jahrzehnten drehte sich die Entwicklung der KI hauptsächlich um die Verbesserung der sprachlichen, mathematischen und logischen Denkfähigkeiten. Die nächste Welle von KI-Fortschritten geht jedoch in Richtung der Entwicklung emotionaler Intelligenz, die es Maschinen ermöglicht, die physische Welt bis zu einem gewissen Grad zu verstehen. Gleichzeitig können wir die Schattenseiten des Einsatzes von KI beobachten. Von der Verzerrung (auch Bias genannt) der Algorithmen über die Diskriminierung bestimmter Geschlechter oder ethnischer Gruppen aufgrund des Lernens aus verschiedenen Quellen bis zu grundlegenden Problemen mit der Fairness – all dies wurde bei verschiedenen KI-Anwendungen festgestellt. Zu den Bereichen, in denen diese Probleme auftreten, gehören Werbung, KI-basierte Rekrutierungssoftware, Vorhersagemodelle für die Anwendung im Gesundheitswesen wie der ada health chatbot und Gesichtserkennungssoftware. Diese Problemfelder werfen Diskussionen über die Ethik der KI auf, denen wir uns in unserem zweiten Artikel zuwenden.
Da zu erwarten ist, dass diese Entwicklungen von KI weiter zunehmen werden, möchten wir deine Aufmerksamkeit auf Künstliche Intelligenz lenken und ein solides und wirklich detailliertes Verständnis für diese Innovationen schaffen. Mit unserem ersten Blogartikel werden wir ein Grundverständnis dafür schaffen, was KI eigentlich ist, über die Geschichte der KI sprechen, eine ganzheitliche Definition von KI suchen und die wichtigsten Schlüsselbegriffe im Zusammenhang mit KI umreißen.